Aim
This vignette describes how to use the debiasR functions to assess and validate adjusted origin-destination (OD) flows derived from mobile phone data. The validation procedures compare the outcome of the bias adjustment methods included in debiasR against a set of target benchmark flows (i.e. adjusted versus benchmark flows). This tells us how close the final adjusted output is to a chosen target benchmark. While the comparison between adjusted versus benchmark flows is the primary focus, debiasR also enables two additional comparisons: raw mobile-phone-derived versus benchmark flows, which tells us about the extent of bias before adjustment; and raw mobile-phone-derived versus adjusted flows, which tells us the extent of adjustment applied to the original raw data.
Important! This vignette focuses on illustrating the use of debiasR validation functions. The focus is not on providing an exhaustive comparison of adjustment methods. Such comparison would require a more comprehensive setup. So do not take the results provided here as evidence to prefer one model over another. A key issue to note is that we are comparing adjustment methods that require benchmark data as input (so they can “see” the target benchmark flow data) against Bayesian models, which do not require such input.
Intuition
To validate adjusted flows, the debiasR framework is organised based on five validation levels, moving from coarse overall checks based on summaries across the whole system of flows, to more granular checks at the local area level. In this way, debiasR recognises the complexity of the validation process, which cannot rely on a single number. Adjusted flows can look good overall and still perform poorly for some origins, destinations or individual OD pairs. In particular, we work with five validation levels.
- Level 1 summarises performance across the whole OD system. This tells us whether a method is broadly close to the benchmark.
- Level 2 compares origin and destination totals, checking whether adjusted flows reproduce total outflows from each origin and total inflows to each destination.
- Level 3 compares individual OD pairs, showing where large local errors remain after adjustment.
- Level 4 assesses whether each origin allocates its flows across destinations in a similar way to the benchmark. This is about the shares across destinations, not only about the total scale.
- Level 5 checks whether remaining residuals show systematic patterns after adjustment. For example, residuals may be larger for large benchmark flows, clustered across neighbouring areas, or associated with an area covariate.
At each level, it is useful to separate error metrics from correlation metrics. Error metrics help us understand whether the numbers are close in magnitude, whereas correlation metrics tell us whether the broader data pattern is similar. A method can have a high correlation with the benchmark and still be too high or too low in absolute terms.
List of validation measures
Let be the adjusted flow from origin to destination , and let be the benchmark flow for the same OD pair. Define the error as . Positive errors mean that the adjusted flow is larger than the benchmark and negative errors that it is smaller. The table uses adjusted-versus-benchmark notation.1
| Metric | Description | Equation |
|---|---|---|
| Mean error | Average signed error; shows whether flows are overestimated or underestimated on average. | |
| Mean absolute error | Average absolute error; shows the typical size of the error, ignoring sign. | |
| Root mean squared error | Error metric that gives more weight to large errors. | |
| Median absolute error | Middle absolute error; less affected by a small number of very large errors. | |
| Mean absolute percentage error | Average absolute error as a percentage of the benchmark flow. | |
| Pearson’s | Linear correlation; shows whether large benchmark flows also tend to be large adjusted flows. | |
| Spearman’s | Rank correlation; shows whether the ordering of flows is similar. | |
| Kullback-Leibler divergence | [Level 4] Directional difference between destination-share distributions. Lower values mean the destinations are allocated more similar to the reference flow. | |
| Jensen-Shannon divergence | [Level 4] Symmetric version of KL divergence. Lower values mean closer allocation. | |
| Residual-versus-benchmark-flow correlation | [Level 5] Association between remaining residuals and benchmark flow size. Values near zero suggest less obvious scale dependence. | |
| Moran’s | [Level 5] Spatial autocorrelation in area-level residuals using user-supplied neighbour links . Positive values suggest neighbouring areas have similar residuals. | |
| Local Moran’s and LISA class | [Level 5] Local spatial association for each area, with permutation pseudo -values and cluster classes such as high-high, low-low, high-low and low-high. | |
| Residual-versus-covariate correlation | [Level 5] Association between area-level residuals and a selected area covariate . Values near zero suggest less obvious covariate-linked error. |
Getting set up
Important! We illustrate how to implement different validation checks for the results of data adjustment methods, across the different levels described above. For level 1, we illustrate a broad selection of data adjustment methods, which include inverse_penetration, selection_rate2, coefficient, bayes_gravity, bayes_gravity_education, bayes_origin_pool and the unadjusted data. These are described in more detail in the adjustment methods section. For simplicity, validation for levels 2-5 is illustrated for a narrower selection of adjustment methods, namely inverse_penetration, coefficient, bayes_gravity_education and unadjusted.
We use debiasR for adjustment and validation, debiasRdata for the empirical travel-to-work data and dplyr and ggplot2 for data handling and plots.
Prepare the validation data. We use LAD travel-to-work data throughout the vignette. The example combines raw mobile phone-derived (MPD) flows with Census benchmark flows and the area information needed by the adjustment methods. All methods are evaluated using the same LADs and origin-destination pairs.
example_data <- debiasR_example_data(
n_areas = Inf,
complete_grid = TRUE,
geography = "lad"
)
mpd_od <- example_data$mpd_od
benchmark_od <- example_data$benchmark_od
coverage_validation <- example_data$coverage
covariates_validation <- example_data$covariates
distance_validation <- example_data$distance
area_names <- covariates_validation |>
dplyr::select(area, name)The main objects are: mpd_od, the raw MPD flows to be adjusted; benchmark_od, the Census flows used as the validation benchmark; coverage_validation, population and active-user coverage by area; covariates_validation, area characteristics used by some adjustment methods; distance_validation, distances between origins and destinations. The resulting data cover 313 LADs and 97969 origin-destination pairs.
Create the results to validate. We first apply three deterministic (non-Bayesian) adjustment methods that will be used in the validation examples below. The function adjust_all_methods() applies the selected methods to the same input data and returns a separate OD table for each method. We also retain the original MPD flows as an unadjusted baseline. This allows us to compare each adjusted result with both the Census benchmark and the data before adjustment.
deterministic_methods <- c(
"inverse_penetration",
"selection_rate2",
"coefficient"
)
deterministic_results <- adjust_all_methods(
mpd_od_df = mpd_od,
coverage_df = coverage_validation,
benchmark_od_df = benchmark_od,
covariates_df = covariates_validation,
covariate_col = "per_level4",
methods = deterministic_methods
)
deterministic_results <- c(
list(unadjusted = dplyr::mutate(mpd_od, flow_adj = flow)),
deterministic_results
)
deterministic_method_results <- deterministic_results |>
validate_flow_prepare_outputs(mpd_df = mpd_od)Bayesian models take considerably longer to fit than the deterministic methods, so we do not fit them while rendering this vignette. Instead, debiasR provides Bayesian adjustment results fitted in advance using the same LAD data. The specifications used to produce these results are described in the adjustment methods section down below. The following code chunk loads the saved results from the installed package and separates them by adjustment method.
bayesian_file <- system.file(
"extdata",
"v07-validation-bayesian-adjusted.csv",
package = "debiasR"
)
bayesian_results <- read.csv(bayesian_file)
bayesian_method_results <- split(
bayesian_results,
bayesian_results$method
)Then, bring together the results for all the adjustment methods described in the adjustment methods section, including those from the deterministic methods obtained via adjust_all_methods() and from the Bayesian methods which we precomputed and just loaded via the code chunk above.
all_method_results <- c(deterministic_method_results, bayesian_method_results)Validation measures
Next we illustrate how to implement different validation checks for the data adjustment methods. We do so across the different levels described above.
Level 1: Overall validation metrics
Level 1 compares complete OD tables. We compare the three deterministic methods fitted above, three precomputed Bayesian models and the unadjusted MPD flows.
level1_methods <- c(
"unadjusted",
deterministic_methods,
"bayes_gravity",
"bayes_gravity_education",
"bayes_origin_pool"
)
level1_method_results <- all_method_results[level1_methods]The debiasR function validate_flow_overall() calculates error and correlation measures across all OD pairs. To apply it to each adjustment method, this vignette uses the exported debiasR method-comparison function validate_flow_overall_methods(). Setting comparisons = "adjusted_vs_benchmark" compares each result with the Census benchmark.
overall_results <- validate_flow_overall_methods(
adjusted_outputs = level1_method_results,
benchmark_od_df = benchmark_od,
comparisons = "adjusted_vs_benchmark"
)We first examine mean absolute error (MAE) and root mean squared error (RMSE). Both are measured in flow counts and lower values indicate closer agreement with the benchmark. The function validate_flow_overall() also calculates other error measures, including mean error, median absolute error and MAPE, as well as correlation measures such as Pearson’s correlation and Spearman’s correlation. The figure below uses validate_flow_plot_metrics() to display MAE and RMSE. The other overall validation measures are retained in overall_results and can be examined separately.
validate_flow_plot_metrics(
overall_results,
error_measures = c("mae", "rmse"),
comparisons = "adjusted_vs_benchmark",
methods = level1_methods,
method_labels = validation_plot_method_labels,
sort = "ascending",
sort_metric = "mae"
)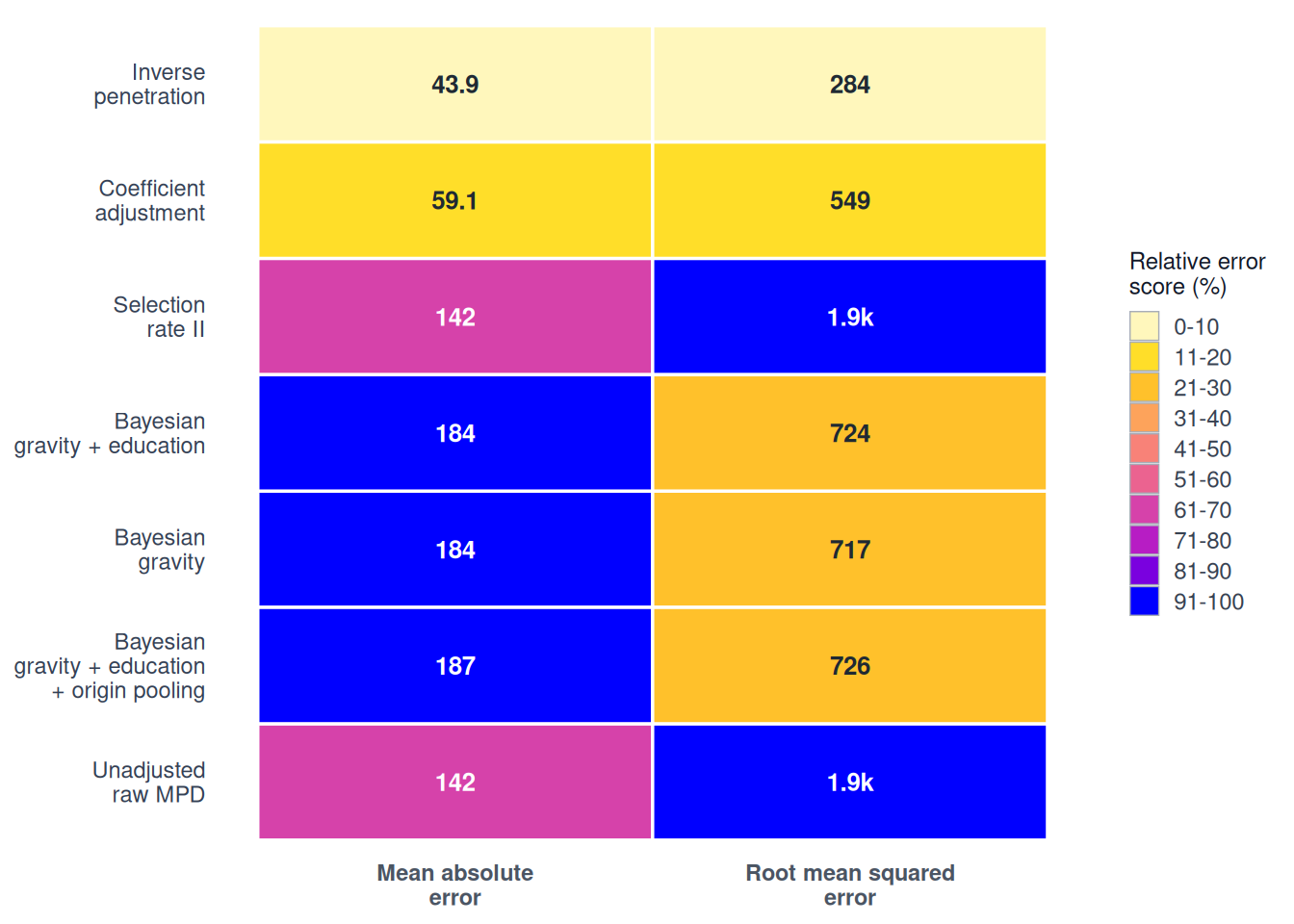
The methods are ordered from lowest to highest MAE. The unadjusted MPD flows are kept at the bottom as a reference, regardless of their MAE. In this example, Inverse penetration has the lowest overall mean absolute error against the benchmark. The strongest Pearson correlation would be for Inverse penetration. These measures can be related but one is about distance from the benchmark, and the other is about similarity in the overall pattern of flows.
Remember! The Bayesian models do not use benchmark OD flows when they are fitted. Some deterministic methods do use benchmark information, so this difference should be considered when interpreting their validation results.
Level 2: Origin and destination marginals
Level 2 compares flows after aggregating them by geographical area. An origin marginal is the total flow leaving an area, while a destination marginal is the total flow entering an area. These totals can reveal geographical differences that are hidden by the system-wide measures used in Level 1.
Remember! From this level onwards, we use four results to keep the detailed plots more readable. These are inverse penetration, coefficient adjustment, Bayesian gravity with education and the unadjusted MPD baseline.
validation_methods <- c(
"inverse_penetration",
"coefficient",
"bayes_gravity_education",
"unadjusted"
)
validation_method_results <- all_method_results[validation_methods]The exported debiasR margin-preparation function validate_flow_margins() sums the OD flows by origin or destination. The exported debiasR method-comparison function validate_flow_overall_methods() then applies the debiasR function validate_flow_overall() to each method.
origin_margins <- validate_flow_margins(
adjusted_outputs = validation_method_results,
benchmark_od_df = benchmark_od,
role = "origin"
)
origin_margin_metrics <- validate_flow_overall_methods(
adjusted_outputs = origin_margins$adjusted_outputs,
benchmark_od_df = origin_margins$benchmark,
comparisons = "adjusted_vs_benchmark"
)
destination_margins <- validate_flow_margins(
adjusted_outputs = validation_method_results,
benchmark_od_df = benchmark_od,
role = "destination"
)
destination_margin_metrics <- validate_flow_overall_methods(
adjusted_outputs = destination_margins$adjusted_outputs,
benchmark_od_df = destination_margins$benchmark,
comparisons = "adjusted_vs_benchmark"
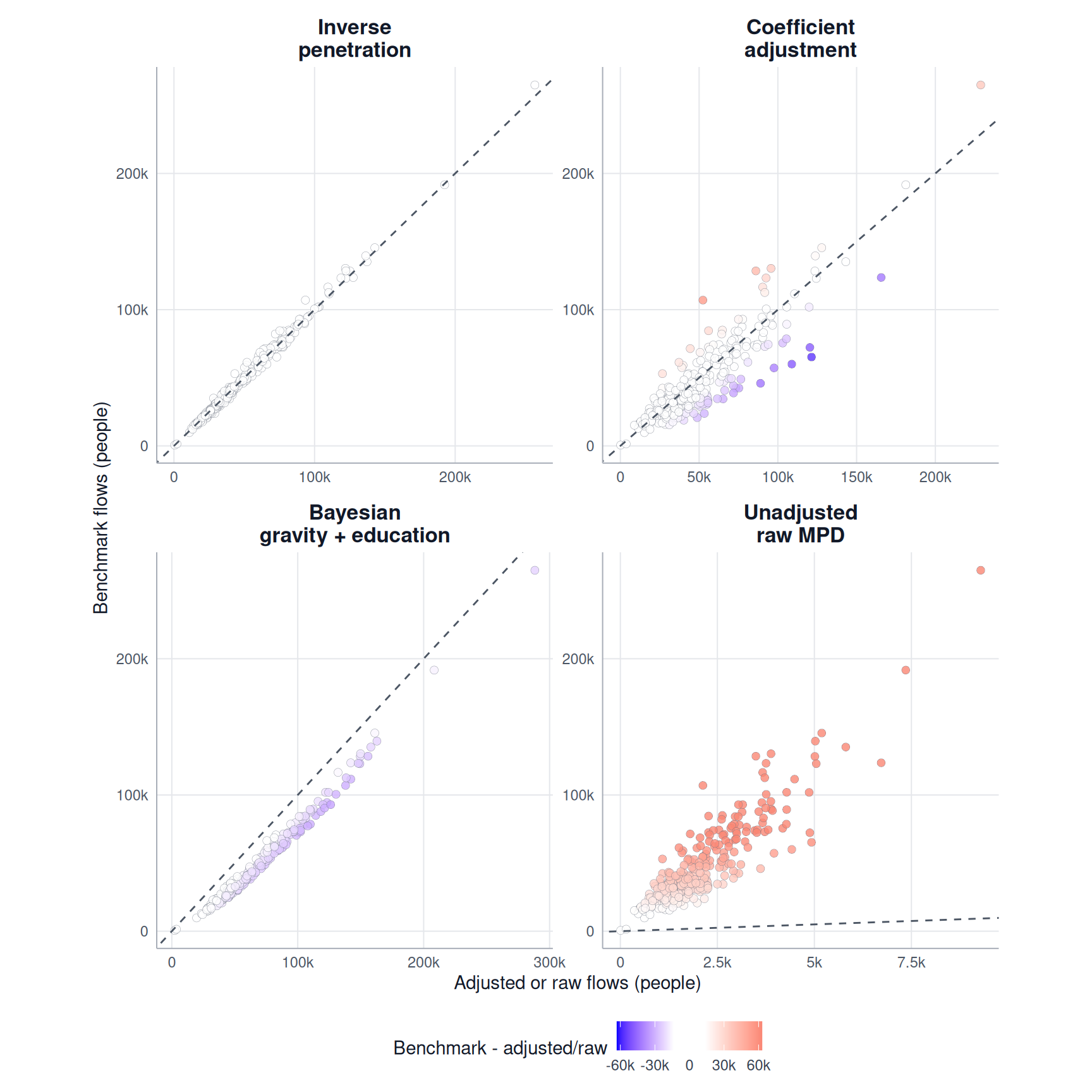
)We produce a first figure to compare origin totals. The exported debiasR method-comparison function validate_flow_residual_methods() applies the function validate_flow_residuals() to each method. The function validate_flow_plot_scatter() plots the results. Each point represents one origin. Points close to the dashed line have similar adjusted and benchmark outflows.
origin_margin_residuals <- validate_flow_residual_methods(
adjusted_outputs = origin_margins$adjusted_outputs,
benchmark_od_df = origin_margins$benchmark,
top_n = 8
)
validate_flow_plot_scatter(
origin_margin_residuals,
comparisons = "adjusted_vs_benchmark",
methods = validation_methods,
method_labels = validation_plot_method_labels,
facet_ncol = 2,
point_size = 2.2,
point_alpha = 0.8,
sort = "ascending"
)
We produce a second figure to compare destination totals. Each point represents one destination. Points close to the dashed line have similar adjusted and benchmark inflows.
destination_margin_residuals <- validate_flow_residual_methods(
adjusted_outputs = destination_margins$adjusted_outputs,
benchmark_od_df = destination_margins$benchmark,
top_n = 8
)
validate_flow_plot_scatter(
destination_margin_residuals,
comparisons = "adjusted_vs_benchmark",
methods = validation_methods,
method_labels = validation_plot_method_labels,
facet_ncol = 2,
point_size = 2.2,
point_alpha = 0.8,
sort = "ascending"
)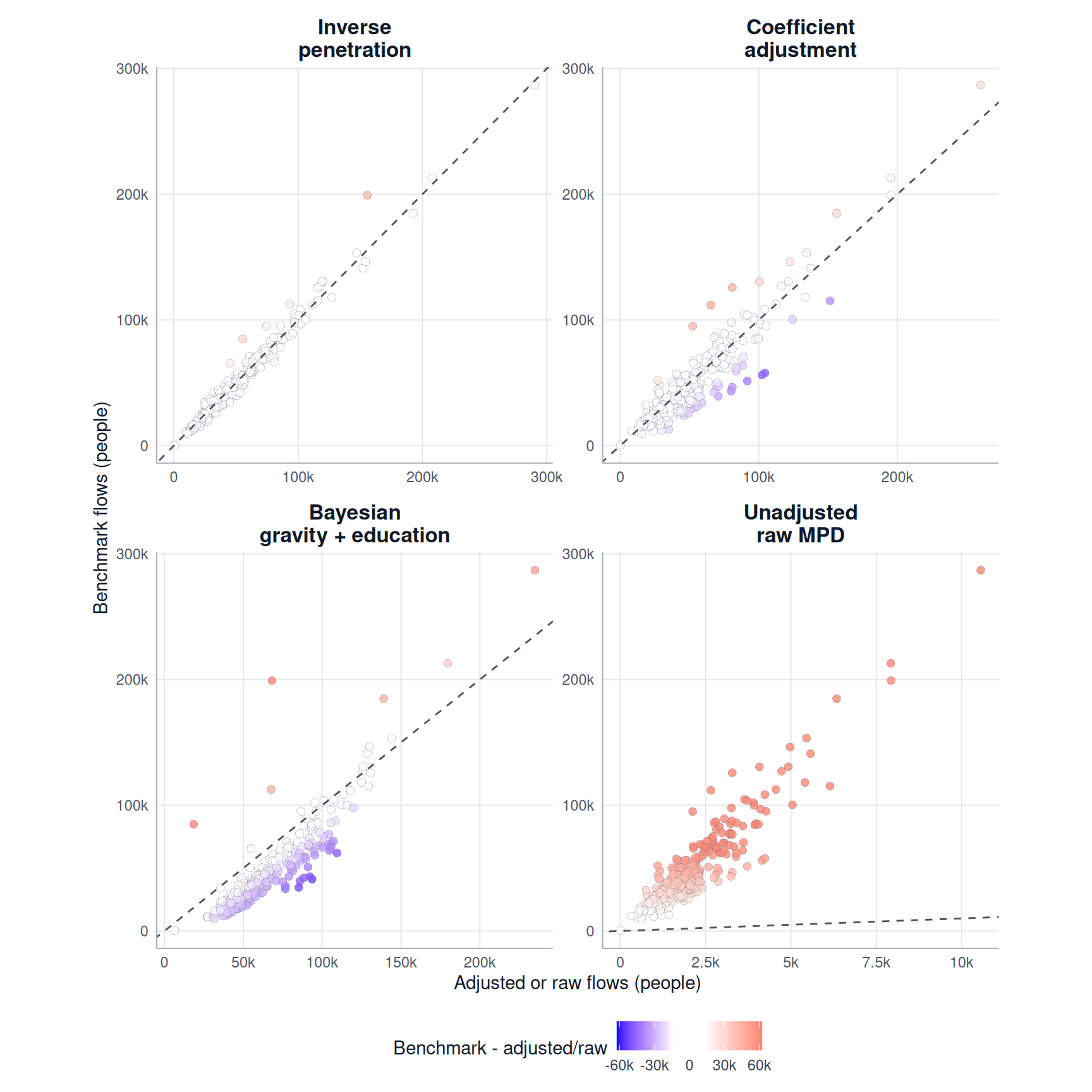
In this example, Inverse penetration has the lowest MAE for origin totals and Inverse penetration has the lowest MAE for destination totals. Generally, an adjustment method may perform differently for the two margins because reproducing total outflows does not necessarily mean that it also reproduces total inflows.
Level 3: Individual OD-flow validation
Level 3 compares individual origin-destination pairs. This is the most granular validation level and is the best place to inspect large local errors. We continue with the four adjustment results selected in Level 2.
The function validate_flow_residuals() calculates signed and absolute residuals for every OD pair. It also identifies the OD pairs with the largest remaining errors. The exported debiasR method-comparison function validate_flow_residual_methods() applies this function to each adjustment method.
flow_residuals <- validate_flow_residual_methods(
adjusted_outputs = validation_method_results,
benchmark_od_df = benchmark_od,
top_n = 12
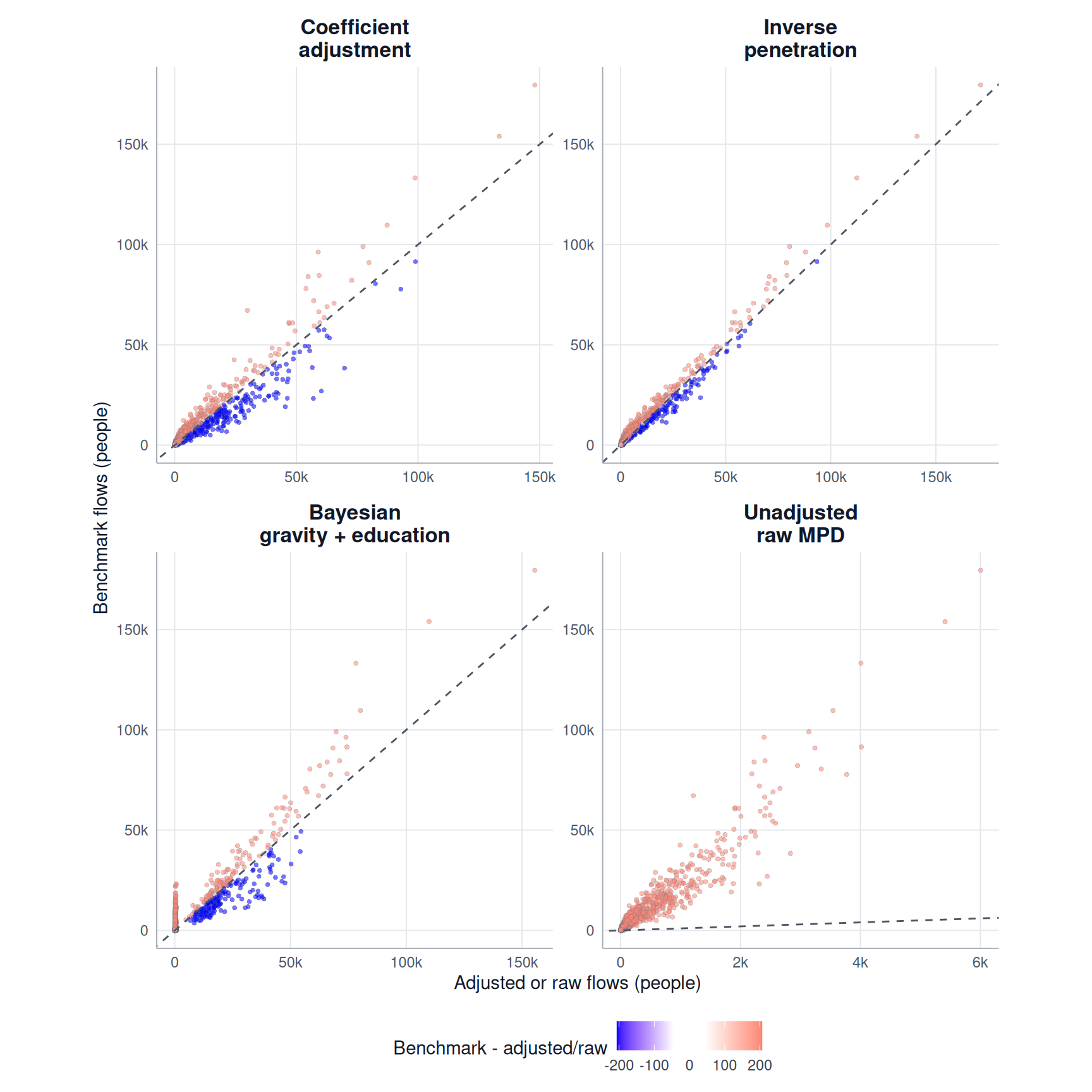
)We first use the function validate_flow_plot_scatter() to compare the adjusted and benchmark flow for every OD pair. Each point represents one origin-destination pair. Points on or near the dashed line have similar adjusted and benchmark flows. Points farther from the line have larger errors. For an adjusted-versus-benchmark comparison, the signed residual is benchmark minus adjusted. A positive residual means that the adjusted flow is below the benchmark, while a negative residual means that it is above the benchmark. Point colour shows this direction and stronger colours indicate larger differences.
validate_flow_plot_scatter(
flow_residuals,
comparisons = "adjusted_vs_benchmark",
methods = validation_methods,
method_labels = validation_plot_method_labels,
facet_ncol = 2,
point_alpha = 0.55,
point_size = 1.2,
sort = "ascending"
)
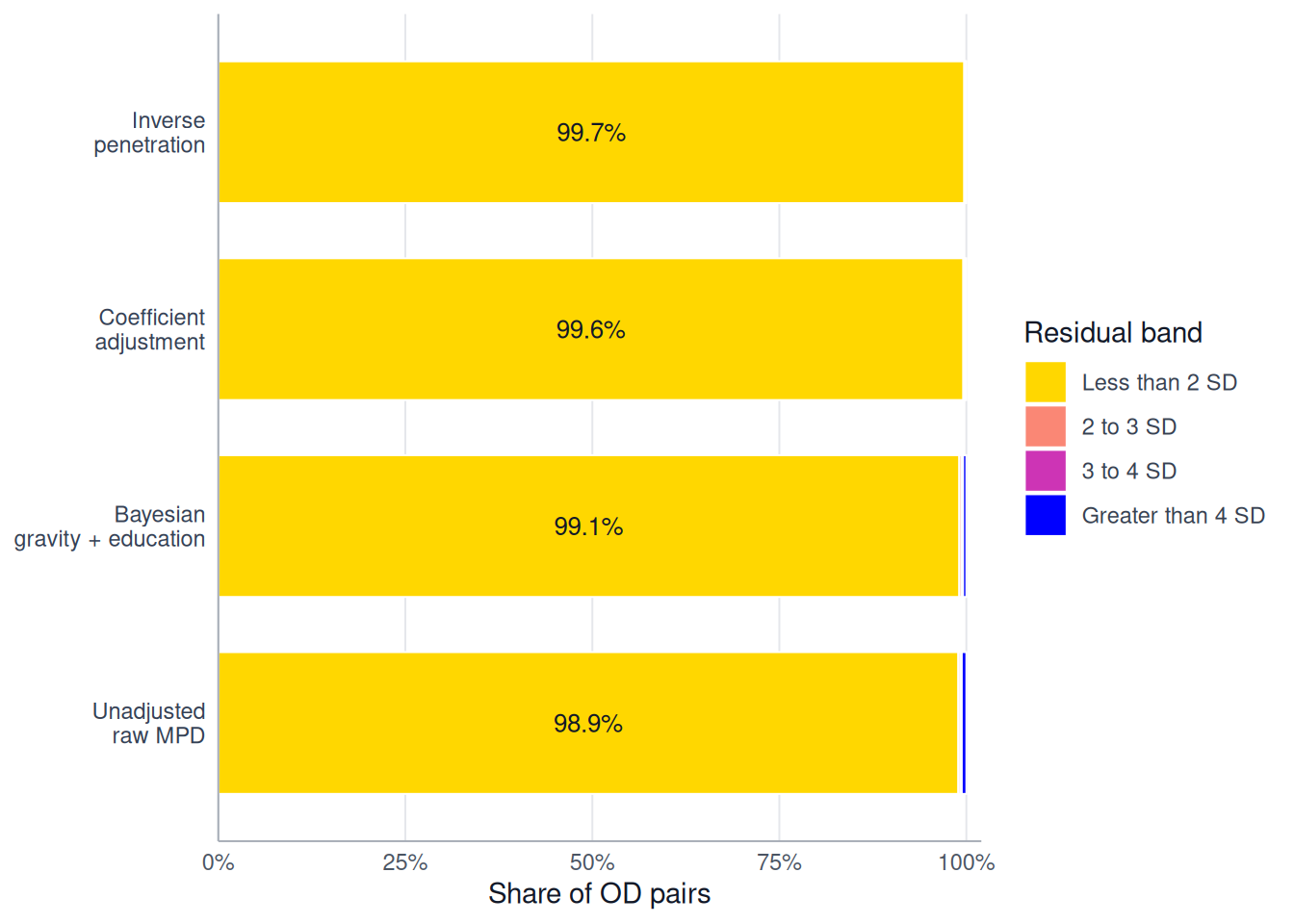
The exported validate_flow_plot_residual_bands() function provides a complementary visualisation. It groups OD pairs according to the absolute size of their residuals, measured in standard-deviation bands. Larger shares in the lower residual bands indicate that more OD pairs are close to the benchmark. Larger shares in the highest band indicate that more OD pairs have severe remaining errors. The methods are ordered by the share of OD pairs in the highest residual band, while the unadjusted MPD flows remain at the bottom as a reference.
validate_flow_plot_residual_bands(
flow_residuals,
comparisons = "adjusted_vs_benchmark",
methods = validation_methods,
method_labels = validation_plot_method_labels,
band_method = "sd",
sd_reference = "adjusted",
orientation = "horizontal",
label_min_share = 4,
sort = "ascending",
sort_metric = "severe_share"
)
Level 4: Distributional allocation validation
Level 4 assesses whether flows from each origin are distributed across destinations in similar proportions to the benchmark. For each origin, the flows to all destinations are converted into shares that sum to one. This separates the pattern of destination choice from the total amount of flow. For example, an adjusted origin total could be too large while still allocating the correct proportions to each destination.
The debiasR function validate_flow_distribution() compares these origin-specific destination shares using Kullback-Leibler divergence and Jensen-Shannon divergence. The Jensen-Shannon divergence provides a symmetric measure of the difference between two distributions. Lower values indicate that the adjusted and benchmark destination shares are more similar. A value of zero would mean that they have identical destination shares. The exported debiasR method-comparison function validate_flow_distribution_methods() applies this function to each adjustment method.
distribution_results <- validate_flow_distribution_methods(
adjusted_outputs = validation_method_results,
benchmark_od_df = benchmark_od,
comparisons = "adjusted_vs_benchmark"
)The function validate_flow_plot_distribution_pairwise() displays the benchmark-weighted mean Jensen-Shannon divergence for each method. The weighting gives more influence to origins with larger benchmark outflows. The methods are ordered from lowest to highest divergence, while the unadjusted MPD flows remain at the bottom as a reference.
validate_flow_plot_distribution_pairwise(
distribution_results,
metric = "jsd",
value = "weighted_mean",
comparisons = "adjusted_vs_benchmark",
methods = validation_methods,
method_labels = validation_plot_method_labels,
plot_type = "comparison",
sort = "ascending"
)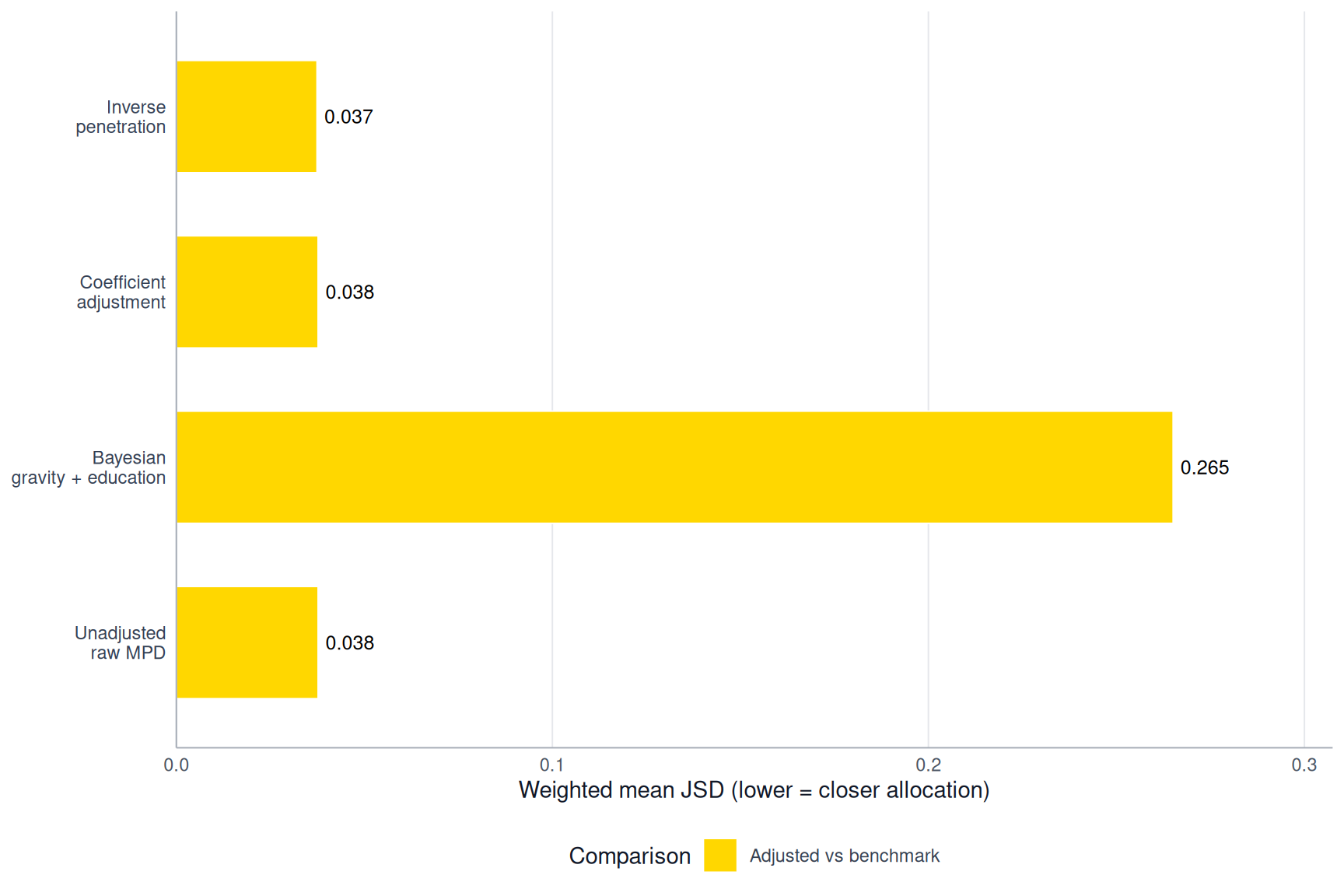
To summarise the comparison, we identify the method with the lowest benchmark-weighted Jensen-Shannon divergence. In this example, Inverse penetration has the lowest benchmark-weighted Jensen-Shannon divergence. This means that its destination shares are the closest to the benchmark shares. It does not necessarily mean that the method has the smallest errors in individual flow values or total flow magnitude.
Level 5: Spatial and residual-structure diagnostics
Level 5 assesses wether the error measures between the adjusted flows and the reference flows follow systematic patterns. A method may perform well on average while still producing errors that are associated with flow size, concentrated in neighbouring areas or related to area characteristics. We propose three types of tests for residual structure:
- correlation between residuals and benchmark flow size
- spatial clustering among origin-level residuals
- correlation between origin-level residuals and an area covariate
In this example, the area covariate is the percentage of residents with Level 4 qualifications or above (per_level4). The spatial clustering checks require a definition of which areas are neighbours. The vignette helper validate_prepare_lad_lisa_inputs() constructs reproducible links between each LAD and its four nearest neighbours using the centroid distances returned by debiasR_example_data(). These are distance-based neighbours. The helper also looks for the LAD boundaries used by the map. It uses a public ONS 2021 boundary file or a local boundary file supplied through DEBIAS_LAD_BOUNDARY_PATH.
validation_lisa_inputs <- validate_prepare_lad_lisa_inputs(
areas = covariates_validation$area,
distance_df = distance_validation,
distance_k = 4
)
structure_neighbors <- validation_lisa_inputs$neighbors
validation_lisa_boundaries <- validation_lisa_inputs$boundaries
validation_lisa_map_note <- validation_lisa_inputs$map_note
structure_covariates <- covariates_validation |>
dplyr::select(area, per_level4)Using deterministic 4 nearest-neighbour links from LAD centroid distances for Local Moran's I. LAD boundaries are available for mapping from: the public ONS 2021 LAD BFC boundary file Scottish background polygons are omitted. Boundary polygons outside the validation support are retained as grey background areas. The debiasR function validate_flow_residual_structure() calculates the residual-flow correlation, Moran’s I, Local Moran’s I and the residual-covariate correlation. The exported debiasR method-comparison function validate_flow_residual_structure_methods() applies this function to each of the four adjustment results.
residual_structure <- validate_flow_residual_structure_methods(
adjusted_outputs = validation_method_results,
benchmark_od_df = benchmark_od,
comparison = "adjusted_vs_benchmark",
spatial_role = "origin",
residual_aggregation = "mean",
area_neighbors = structure_neighbors,
local_moran = TRUE,
covariate_df = structure_covariates,
covariate_col = "per_level4",
methods = validation_methods,
local_moran_nsim = 199,
local_moran_seed = 20260613
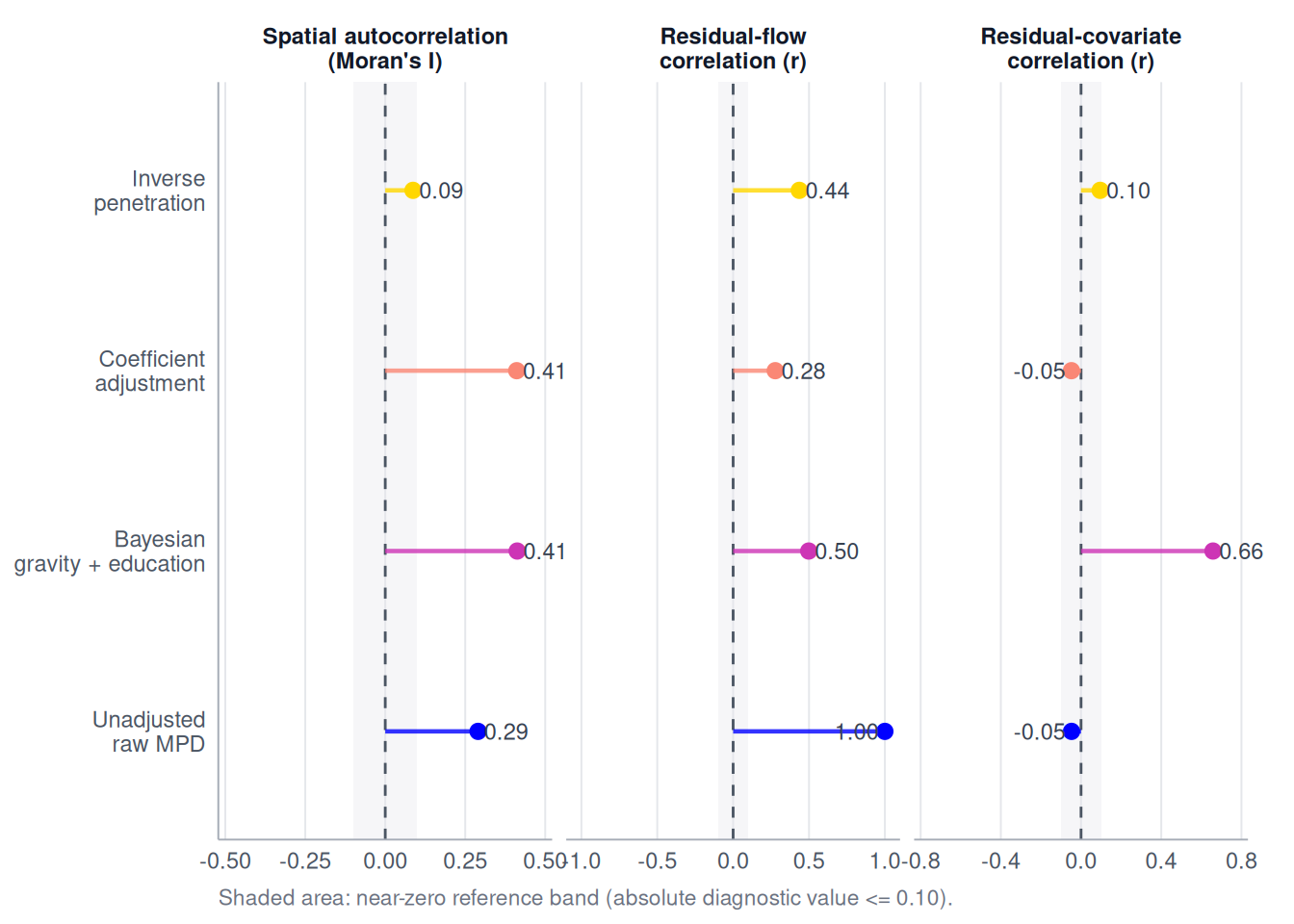
)The function validate_flow_plot_structure() summarises the three level 5 tests proposed above. A residual-flow correlation close to zero indicates that errors do not have an obvious linear relationship with benchmark flow size. A residual-covariate correlation close to zero indicates less evidence of a linear relationship with the selected area characteristic. For the spatial clustering test, we look at Moran’s , which measures whether neighbouring areas have similar residuals. Positive values indicate spatial clustering, while values near zero indicate less evidence of an overall spatial pattern.
validate_flow_plot_structure(
residual_structure,
methods = validation_methods,
method_labels = validation_plot_method_labels
)
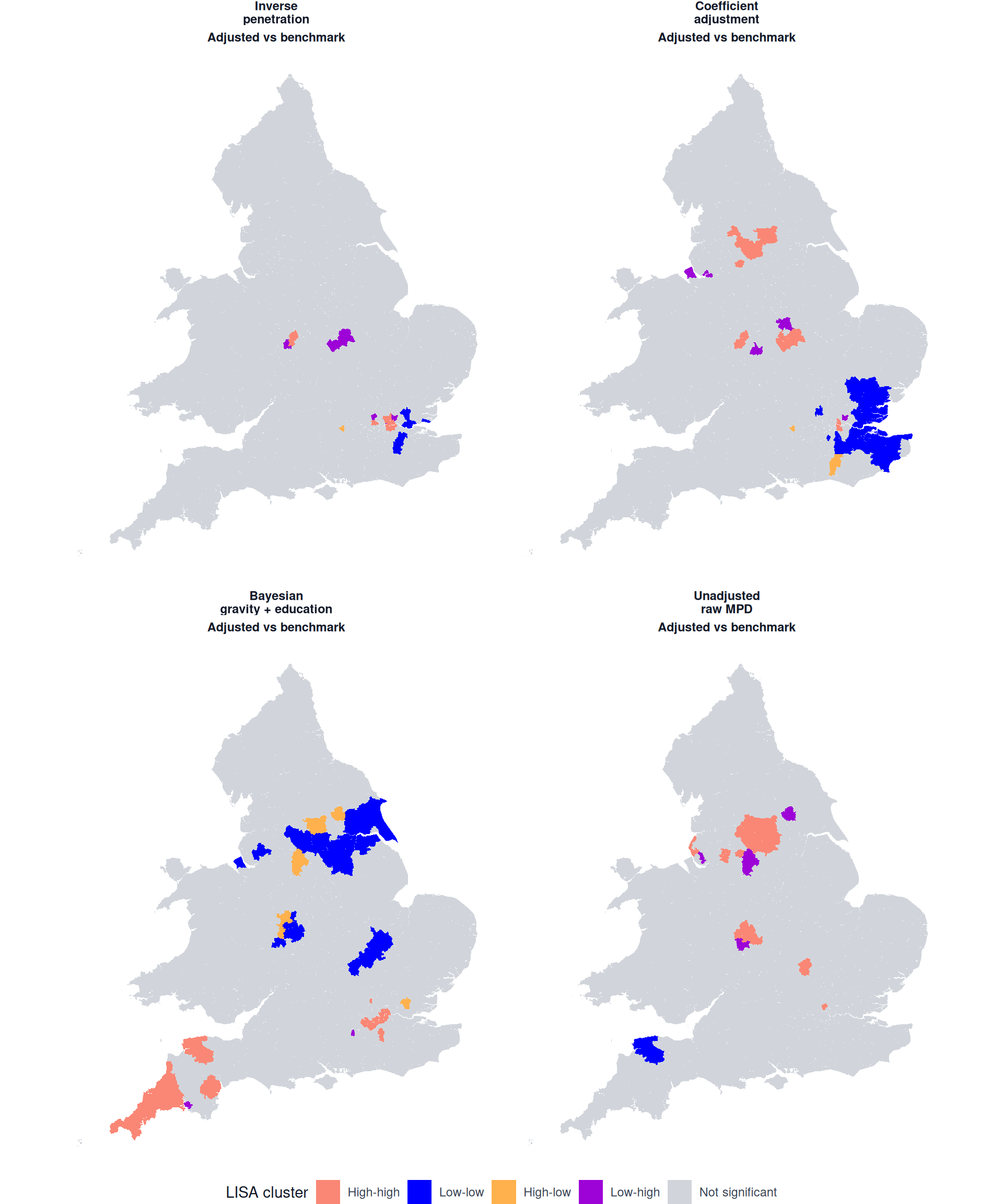
While global Moran’s summarises spatial clustering across all areas, the local Moran’s examines each area separately and assigns it to a Local Indicators of Spatial Association (LISA) class. For the adjusted-versus-benchmark comparison, positive residuals mean that adjusted flows are below the benchmark and negative residuals mean that they are above it. Therefore, a high-high area in a LISA map has a positive residual and is surrounded by areas with positive residuals. A low-low area has a negative residual and is surrounded by areas with negative residuals. High-low and low-high areas are local spatial outliers. The function validate_flow_plot_lisa_map() maps these local patterns. Areas without evidence of local spatial association at the selected threshold are shown as not significant. The map uses raw permutation pseudo -values of 0.05, so it should be treated as an exploratory screen rather than a multiple-testing-adjusted decision rule.
if (is.null(validation_lisa_boundaries)) {
cat(validation_lisa_map_note, "\n")
} else {
validate_flow_plot_lisa_map(
residual_structure,
boundaries = validation_lisa_boundaries,
boundary_area_col = "area",
comparisons = "adjusted_vs_benchmark",
methods = validation_methods,
method_labels = validation_plot_method_labels,
cluster_col = "lisa_quadrant",
p_value_col = "p_value",
p_value_threshold = 0.05,
missing_fill = "#D1D5DB",
boundary_colour = NA,
boundary_linewidth = 0
)
}
Recommendation
Our recommendation is to adopt a sequence approach to validation. First, we suggest to analyse the overall metrics to assess if the resulting adjusted flows are broadly closer to the benchmark. Second, we recommend evaluating origin and destination marginal diagnostics to determine the precision of correction for area totals and identify systematic under- or over-estimation for specific areas. Third, we suggest inspecting individual origin-destinations pairs to evaluate corridors of special interest, such as origin-destinations pairs that typically have large amounts of interaction.
The validation methods presented here offer quantitative evidence to assist in the selection of which method to use. However, this decision depends on a combination of qualitative and quantitative factors:
- Data availability. Adjustment methods require different levels of inputs. Simpler deterministic adjustment methods generally require fewer data inputs. Yet, they often require target benchmark flow data and these are precisely the data inputs that we often do not have. Benchmark flow data often come from censuses, which are considered the gold standard, but these data are generally collected every ten or five years and are outdated when a crisis occurs or a new evaluation of mobility is needed to support humanitarian operations, planning or policy decisions. Hence, using an adjustment method requiring census benchmark data would produce misleading results if it represented the mobility network at the time of the census rather than the mobility system during the period of interest. An adjustment method, such as the proposed Bayesian multilevel modelling approach, that is not reliant on such inputs may be more appropriate in such scenarios.
-
Required measurement precision. Adjustment methods have varying levels of precision in terms of scale reproducing population numbers. Prior work has focused on satisfying the requirement of proportionality by assessing the linear correlation between raw and/or adjusted mobile-phone-derived flows and benchmark flows. Yet, such assessment does not guarantee that raw or adjusted flows provide an accurate estimate in population numbers. Except for the selection rate II method, all the methods in
debiasRseek to provide population numbers. -
Time constraint. The adjustment methods in
debiasRmay demand more or less time. Such demand will depend on processes such as data gathering, data processing and calibrating adjustment methods. As suggested above, the use of digital trace data is often triggered by the rapid and urgent need to have “rough” population numbers to inform humanitarian, planning or policy decisions, to address a crisis or new intervention.
Adjustment methods used in this vignette
The table below states which adjustment methods are used in this vignette and the data inputs required by each of them. Not all methods learn from the same information. Yet, for illustration purposes, we still validate all outputs on the same benchmark OD table and the same OD rows.
| Method | Main fitting inputs | Benchmark used to fit | Validation role |
|---|---|---|---|
| Unadjusted raw MPD | Raw MPD flows only | No | Raw baseline |
| Inverse penetration | Raw MPD flows and origin/destination coverage rates | No | Coverage weighting |
| Selection rate II | Raw MPD flows, coverage rates and benchmark origin totals | Yes, benchmark origin totals | Coverage weighting with calibration |
| Coefficient adjustment | Raw MPD flows and benchmark OD cells | Yes, benchmark OD cells | Benchmark-OD calibration |
| Bayesian gravity | Raw MPD flows, coverage rates, population and distance | No benchmark OD cells | Bayesian coverage-offset |
| Bayesian gravity + education | Raw MPD flows, coverage rates, population, distance, rural-share and education covariates | No benchmark OD cells | Bayesian coverage-offset |
| Bayesian gravity + education + origin pooling | Raw MPD flows, coverage rates, population, distance, covariates and origin pooling | No benchmark OD cells | Bayesian coverage-offset |