Aim
This vignette shows how to measure population coverage bias in mobile-phone-derived data. The goal is to compare how many people are captured in the digital trace data with how many people live in each area according to a trusted benchmark. We use the notation introduced in the previous vignette. For each spatial unit , Local Authority Districts (LADs) in our case, let:
- be the observed digital trace user count
- be the benchmark population count from the 2021 Census
- be the active-user coverage rate
- be the coverage bias
where and . So, if an area has , the digital trace data cover about 4 people per 100 residents, and the coverage bias is . Lower values of mean better coverage.
Load data
We use the LAD coverage table from debiasRdata. The table contains benchmark Census population counts and Locomizer-derived digital trace population counts for each LAD.
coverage <- debiasRdata::coverage_lad
head(coverage) date name code population user_count
1 2021 Hartlepool E06000001 92338 1207
2 2021 Middlesbrough E06000002 143926 1028
3 2021 Redcar and Cleveland E06000003 136531 1144
4 2021 Stockton-on-Tees E06000004 196595 1755
5 2021 Darlington E06000005 107799 1165
6 2021 Halton E06000006 128478 1744measure_bias() expects the benchmark population column to be called population and the digital trace population column to be called user_count. These names are already used in coverage_lad; we only rename the area code to area so the later residual assessment function has a standard area column identifier.
date name area population user_count
1 2021 Hartlepool E06000001 92338 1207
2 2021 Middlesbrough E06000002 143926 1028
3 2021 Redcar and Cleveland E06000003 136531 1144
4 2021 Stockton-on-Tees E06000004 196595 1755
5 2021 Darlington E06000005 107799 1165
6 2021 Halton E06000006 128478 1744Measuring coverage bias
The function measure_bias() calculates the active-user coverage rate and the coverage bias . The function returns these as coverage_score, which is and coverage_bias, which is . Below we print its output:
bias_lad <- measure_bias(coverage)
bias_lad |>
select(area, name, population, user_count, coverage_score, coverage_bias) |>
head() area name population user_count coverage_score
1 E06000001 Hartlepool 92338 1207 0.013071542
2 E06000002 Middlesbrough 143926 1028 0.007142559
3 E06000003 Redcar and Cleveland 136531 1144 0.008379049
4 E06000004 Stockton-on-Tees 196595 1755 0.008926982
5 E06000005 Darlington 107799 1165 0.010807150
6 E06000006 Halton 128478 1744 0.013574308
coverage_bias
1 0.9869285
2 0.9928574
3 0.9916210
4 0.9910730
5 0.9891928
6 0.9864257A useful first summary is the overall coverage across all LADs. So, across England and Wales as a whole, what share of the Census population is captured in the digital trace population count?
bias_lad |>
summarise(
lad_count = n(),
census_pop = sum(population),
digital_trace_pop = sum(user_count),
overall_coverage = sum(user_count) / sum(population),
overall_coverage_bias = 1 - overall_coverage
) lad_count census_pop digital_trace_pop overall_coverage overall_coverage_bias
1 331 59597541 654130.2 0.01097579 0.9890242While these overall numbers are quite informative, they can hide important local differences. A data source may have reasonable national coverage while still covering some places much better than others.
Comparing coverage across spatial units
The next step is to look at variation across spatial units or LADs. The areas with the lowest values of have the strongest digital trace coverage. The areas with the highest values of have the weakest coverage.
bias_lad |>
arrange(coverage_bias) |>
select(area, name, population, user_count, coverage_score, coverage_bias) |>
head() area name population user_count coverage_score coverage_bias
1 E07000069 Castle Point 89587 1980 0.02210142 0.9778986
2 E07000098 Hertsmere 107827 2164 0.02006918 0.9799308
3 E07000066 Basildon 187571 3612 0.01925671 0.9807433
4 E07000113 Swale 151676 2916 0.01922519 0.9807748
5 E07000074 Maldon 66208 1264 0.01909135 0.9809087
6 E07000075 Rochford 85661 1634 0.01907519 0.9809248A histogram gives a view of how uneven coverage is across LADs.
ggplot(bias_lad, aes(x = coverage_bias)) +
geom_histogram(bins = 30, colour = "white", fill = "#356859") +
labs(
x = expression("Coverage bias, " * b[i]),
y = "Number of LADs",
title = "Distribution of population coverage bias across LADs"
) +
theme_minimal()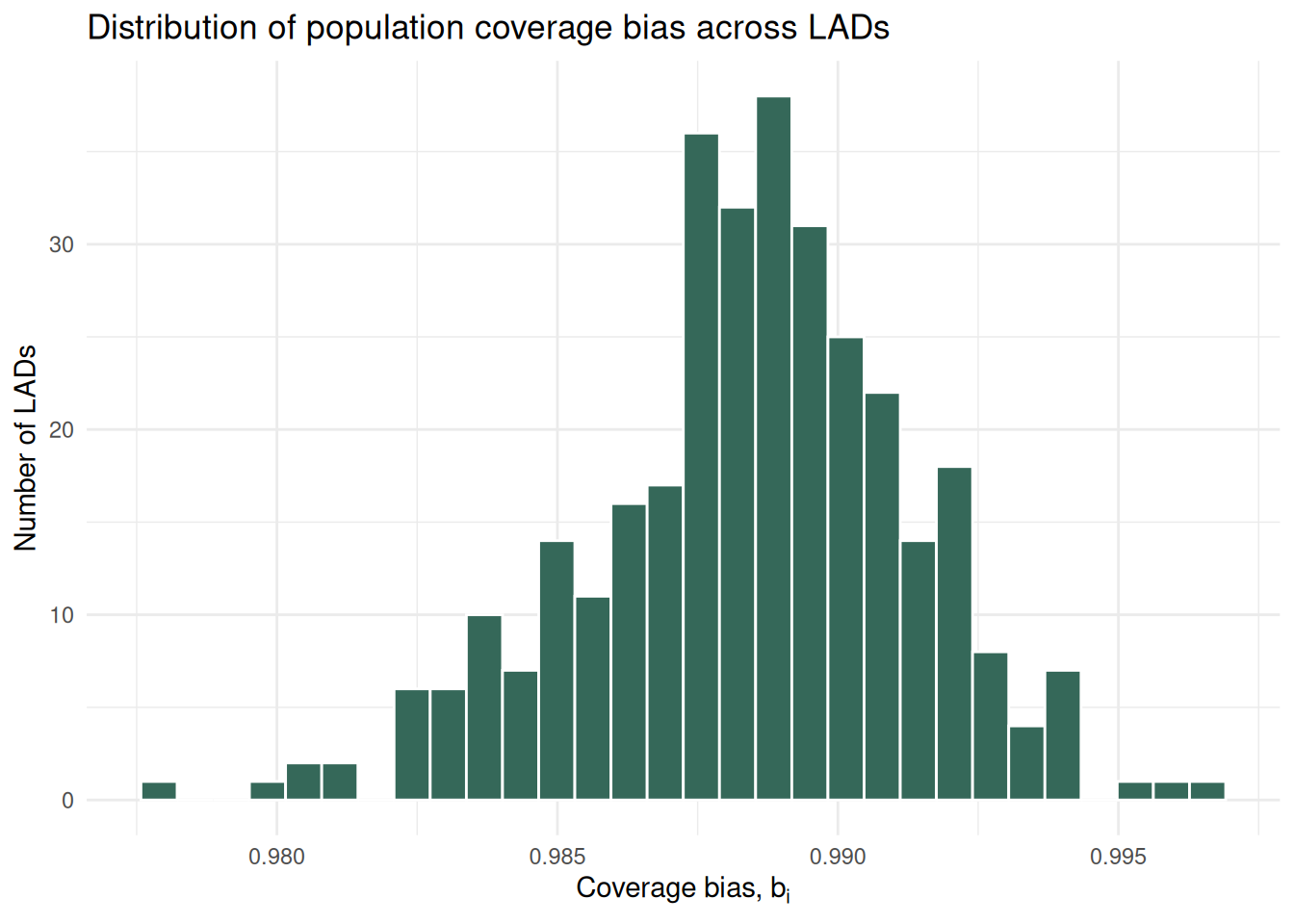
Assessing bias distribution
Coverage rates tell us the extent to which the digital trace data captures the population in each area relative to its own benchmark population. A related question is whether the active-user population is distributed across areas in the same proportions as the benchmark population. For example, if an LAD contains 3% of the benchmark population, does the active-user dataset also place about 3% of active users in that LAD? The function measure_bias_distribution() summarises this distributional comparison. It uses the benchmark population shares as the reference distribution and active user shares as the comparison distribution. Lower KL divergence and Jensen-Shannon divergence mean the active-user distribution is closer to the benchmark population distribution.
distribution_bias <- measure_bias_distribution(
coverage_df = coverage,
area_col = "area",
population_col = "population",
user_count_col = "user_count"
)The area-level output shows which LADs contribute most to the difference between the two distributions. Positive share differences mean an LAD accounts for a larger share of active users than of the benchmark population. Negative values mean the opposite.
distribution_bias$area_level |>
dplyr::left_join(
coverage |> dplyr::select(area, name),
by = "area"
) |>
dplyr::mutate(
abs_share_difference = abs(share_difference_user_minus_population)
) |>
dplyr::arrange(dplyr::desc(abs_share_difference)) |>
dplyr::select(
area,
name,
population_share,
user_share,
share_difference_user_minus_population,
kl_contribution,
jsd_contribution
) |>
head() area name population_share user_share
1 E08000025 Birmingham 0.019210843 0.014197479
2 E08000032 Bradford 0.009168365 0.005338387
3 E08000003 Manchester 0.009261087 0.005936127
4 E06000016 Leicester 0.006184332 0.003251646
5 E09000030 Tower Hamlets 0.005206691 0.002308409
6 E06000035 Medway 0.004694372 0.007466403
share_difference_user_minus_population kl_contribution jsd_contribution
1 -0.005013364 0.005809560 0.0001887929
2 -0.003829978 0.004958577 0.0002558133
3 -0.003324960 0.004119003 0.0001833443
4 -0.002932686 0.003975646 0.0002316865
5 -0.002898282 0.004235050 0.0002868141
6 0.002772032 -0.002178419 0.0001593675Another useful and more visual check consists in inspecting the relationship between the benchmark population and the observed digital trace user counts. Larger LADs should generally have larger user counts. If they did not, the data would be a poor population proxy. The figure below displays this relationship as a scatter plot, where each dot represents a spatial unit. There seems to be a reasonable level of correlation between the benchmark population and the observed digital trace counts. However, further investigation of the relationship is needed, as it can tell us more about what areas may be under-represented in the digital trace data and why.
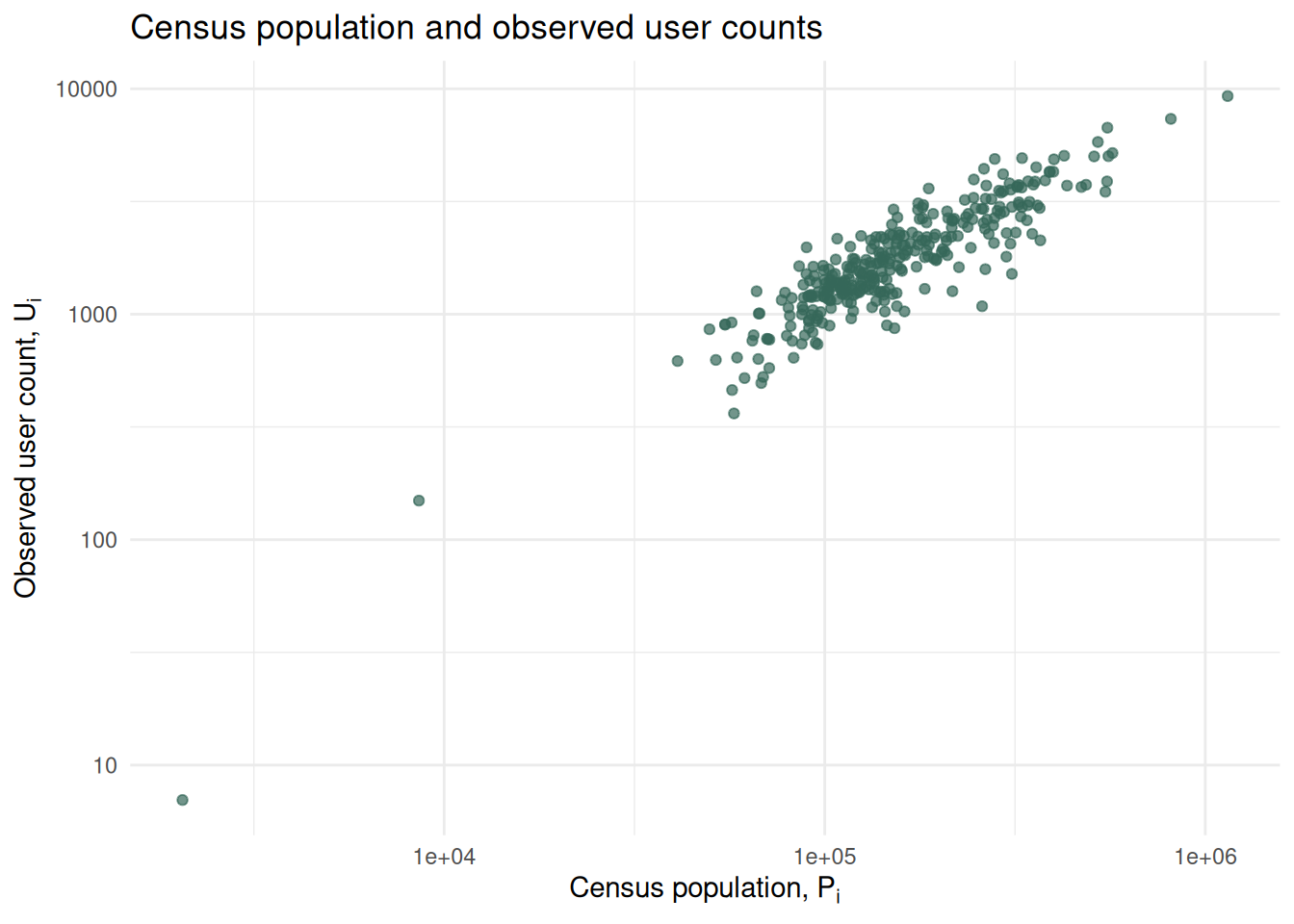
Proportional baseline model
To further investigate the relationship between the benchmark population and observed digital trace user counts, we can start by fitting a linear model. If the level of population coverage was the same across all LADs, we would expect the observed data in the scatter plot to align perfectly to the proportionality line. We call this model the proportional baseline. The left panel in the figure below displays the same scatter plot we had above, plus the proportional baseline model. Although the points follow the overall relationship reasonably well, the residuals in the right panel reveal substantial differences between LADs. These residuals show where observed user counts are higher or lower than expected under constant coverage. We can then investigate whether these differences are associated with the population characteristics of each LAD. Systematic relationships would suggest that some population groups or types of areas are more visible in the digital trace data than others.
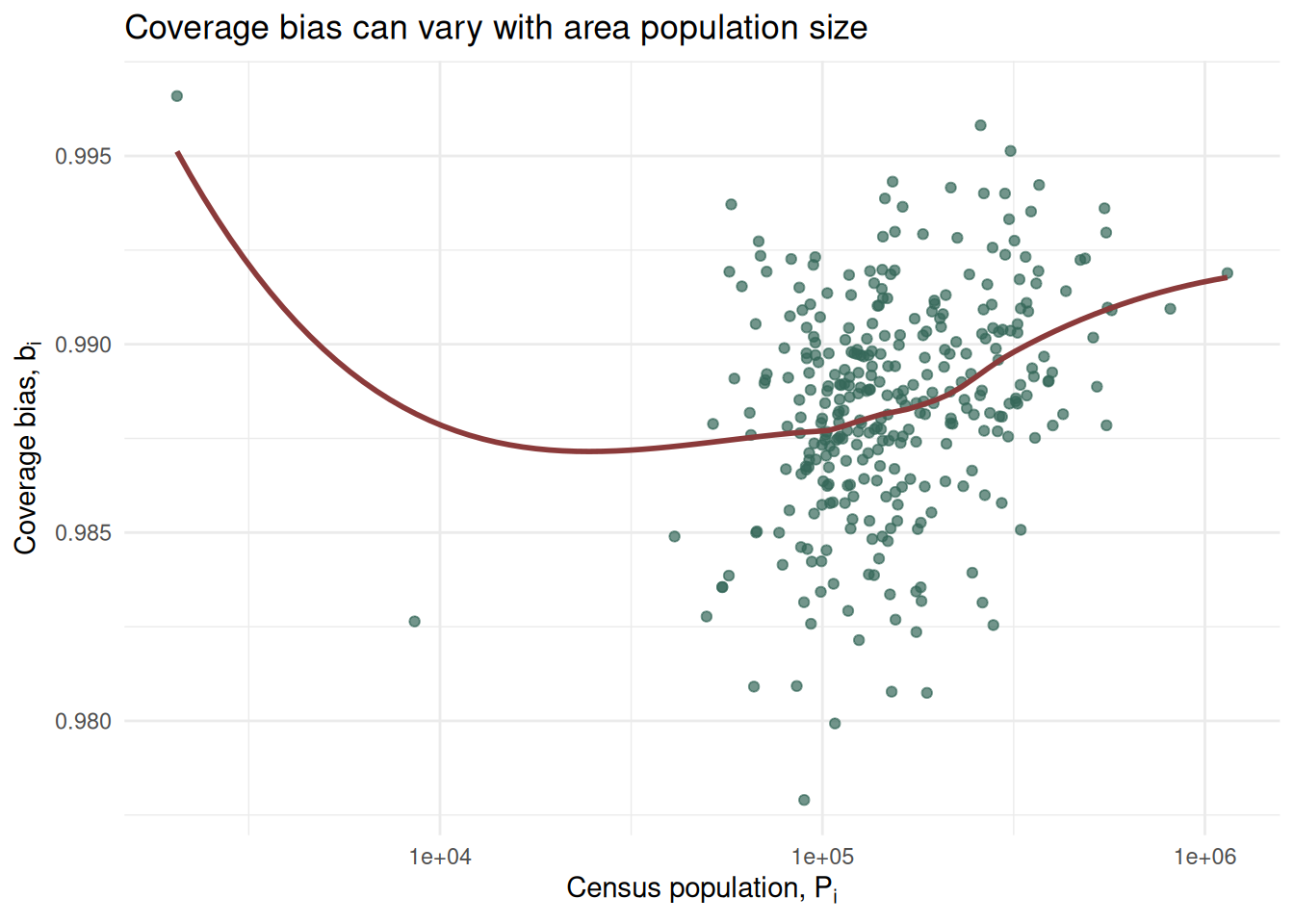
The function validate_bias_residual_structure() calculates the proportional baseline model and returns expected user counts under the equal-coverage assumption, plus several residual measures for each LAD. The object returned by validate_bias_residual_structure() is a list. Each component gives different information:
-
summarygives the overall active-user coverage rate, the number of areas and summary measures of the residuals -
residual_definitionsrecords how the different residuals are defined and how to interpret their sign -
moran_ireports spatial autocorrelation diagnostics when a neighbour table is supplied; here it is returned with missing values because we have not provided spatial neighbours -
benchmark_flow_correlationreports correlations between residuals and benchmark origin or destination flow totals when a benchmark OD-flow table is supplied; here it is empty because this section only uses population counts -
covariate_correlationreports the correlation between residuals and a selected area-level covariate when one is supplied; here it is returned with missing values because we have not yet added covariates -
area_levelcontains one row per LAD with the observed count, expected count, active-user coverage rate and residuals -
map_datacontains the same area-level residuals, optionally joined to geometry or coordinate data when these are supplied
Some optional components may also appear if extra inputs are provided. For example, benchmark_flow_data is returned when benchmark OD flows are supplied, covariate_data is returned when a covariate is supplied and plots is returned when make_plots = TRUE.
bias_residuals <- validate_bias_residual_structure(
coverage_df = coverage,
coverage_area_col = "area",
population_col = "population",
user_count_col = "user_count"
)For the rest of this vignette, we focus on three components: summary, residual_definitions and area_level. The summary component provides a compact description of the proportional baseline, where global_coverage_score is the share of the total benchmark population captured by the digital trace data across all LADs combined. This is the constant coverage rate used to calculate the expected user count in each LAD.
as.data.frame(bias_residuals$summary) |>
select(
residual_type,
total_population,
total_user_count,
global_coverage_score
) residual_type total_population total_user_count global_coverage_score
1 coverage_score 59597541 654130.2 0.01097579The residual_definitions component is a useful reminder of the residuals available in the output. By default, the selected residual is coverage_score_residual.
as.data.frame(bias_residuals$residual_definitions) |>
select(
residual,
definition
) |>
head(2) residual definition
1 coverage_score_residual coverage_score - global_coverage_score
2 user_count_residual user_count - expected_user_countThe area_level component is the main table used for interpretation. It keeps the original population and user counts, adds the expected user count under the proportional baseline and then calculates residuals for each LAD.
bias_residuals$area_level |>
select(
area,
population,
user_count,
expected_user_count,
coverage_score,
coverage_score_residual
) |>
head() area population user_count expected_user_count coverage_score
1 E06000001 92338 1207 1013.483 0.013071542
2 E06000002 143926 1028 1579.702 0.007142559
3 E06000003 136531 1144 1498.536 0.008379049
4 E06000004 196595 1755 2157.786 0.008926982
5 E06000005 107799 1165 1183.179 0.010807150
6 E06000006 128478 1744 1410.148 0.013574308
coverage_score_residual
1 0.0020957494
2 -0.0038332327
3 -0.0025967426
4 -0.0020488102
5 -0.0001686417
6 0.0025985164The default residual, coverage_score_residual, is local coverage minus overall coverage , where is the overall active-user coverage rate. Positive values mean the LAD is covered more than expected under the proportional baseline. Negative values mean the LAD is covered less than expected. Because the vignette focuses on bias, we also create a bias residual, defined as where . Then, positive values of mean the LAD has more coverage bias than expected under the proportional baseline. Negative values mean it has less coverage bias than expected. The largest positive residuals are LADs where digital trace coverage is lower than expected from the national baseline. Similarly, the most negative residuals are LADs where coverage is higher than expected.
We can visualise the distribution of residual bias in a histogram.
ggplot(residual_lad, aes(x = residual_bias)) +
geom_vline(xintercept = 0, colour = "grey40") +
geom_histogram(bins = 30, colour = "white", fill = "#356859") +
labs(
x = expression("Bias residual relative to proportional baseline, " * r[i]),
y = "Number of LADs",
title = "Some LADs depart from the constant-coverage baseline"
) +
theme_minimal()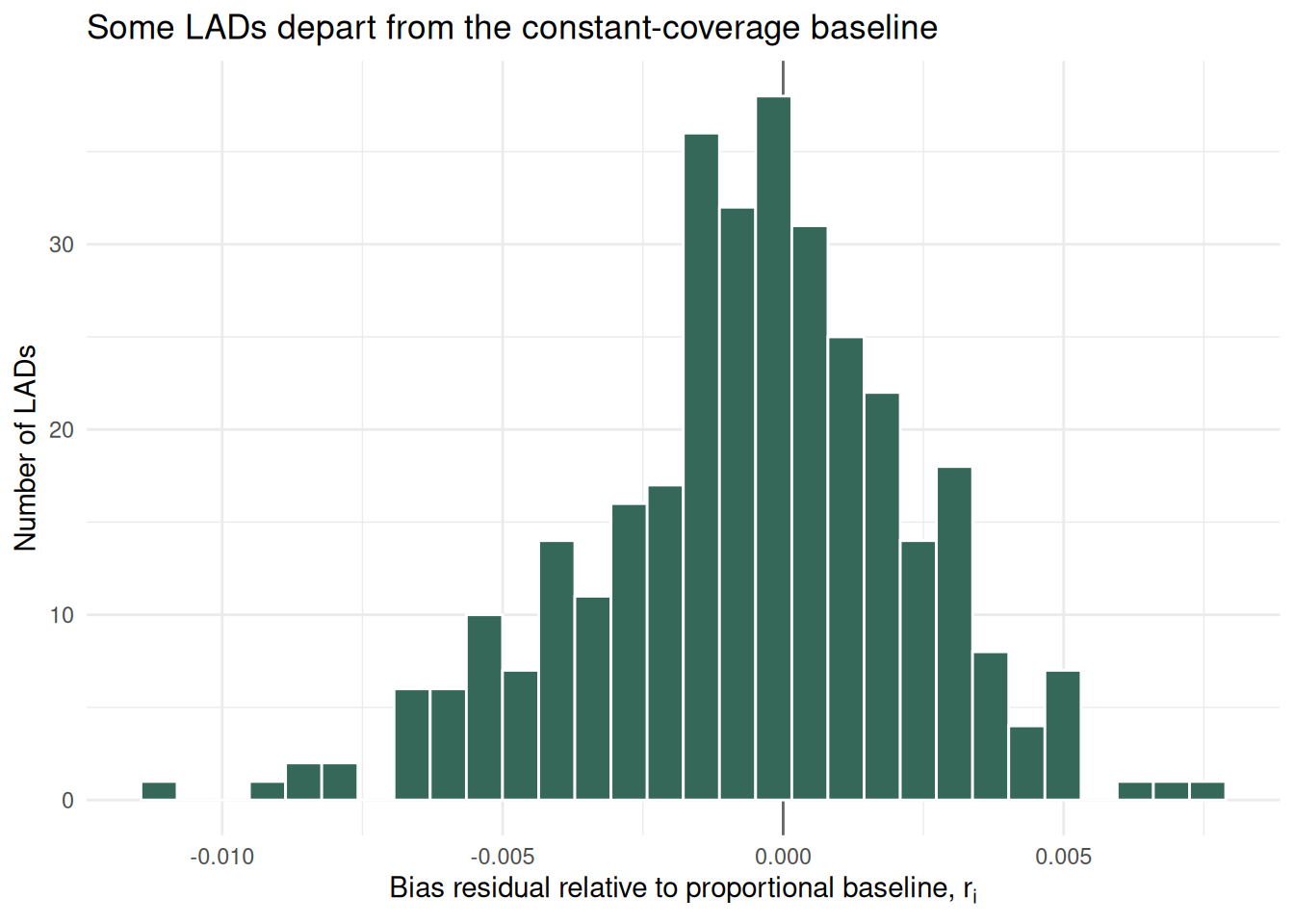
Interpretation
We have seen that population coverage bias tells us how much of the benchmark population is visible in the digital trace data. But, is this coverage roughly constant across places, or are some LADs more visible in the data than others? In practice, we find that coverage tends to be uneven. Some LADs are overcovered or undercovered relative to the national average coverage rate. These departures raise a representativeness question: why is a particular place more or less visible than expected? One possibility is that the area contains a larger share of population groups (e.g. people aged 20-29) that are more or less likely to appear in the digital trace data.
The key message is that high overall coverage is not the same as representativeness. A data source can capture many people in total while still representing some places and population groups better than others. So, our next step is to ask whether residual coverage bias is associated with area characteristics such as age structure, socioeconomic composition or rurality.